
PyTorch tarining loop and callbacks
16 Mar 2019 by dzlabA basic training loop in PyTorch for any deep learning model consits of:
- looping over the dataset many times (aka epochs),
- in each one a mini-batch of from the dataset is loaded (with possible application of a set of transformations for data augmentation)
- zeroing the grads in the optimizer
- performing a forward pass on the given mini-batch of data
- calculating the losses between the result of the forward pass and the actual targets
- using these loosses perform a backward pass to update the weights of the model
- in each one a mini-batch of from the dataset is loaded (with possible application of a set of transformations for data augmentation)
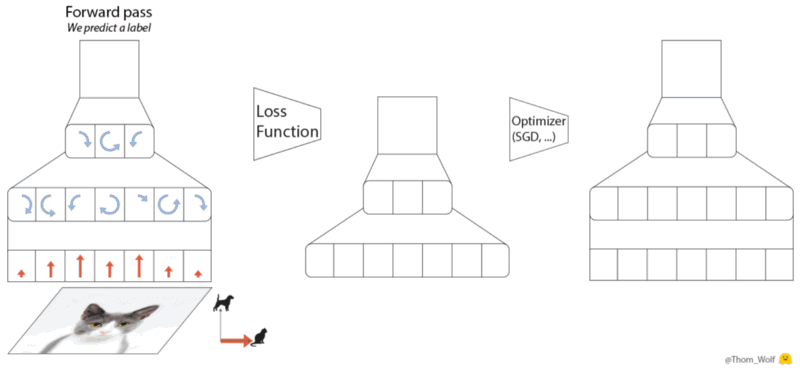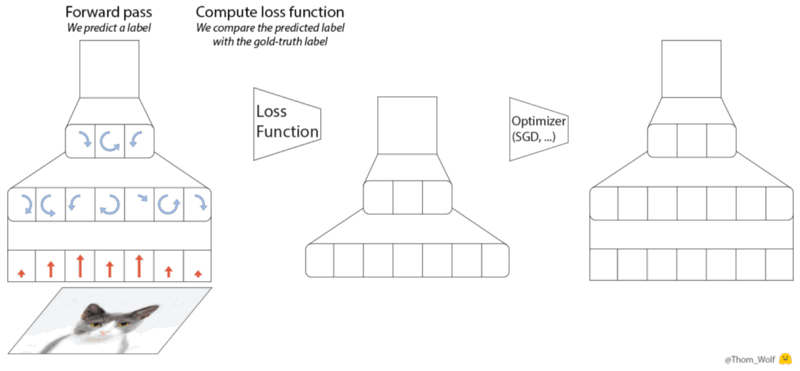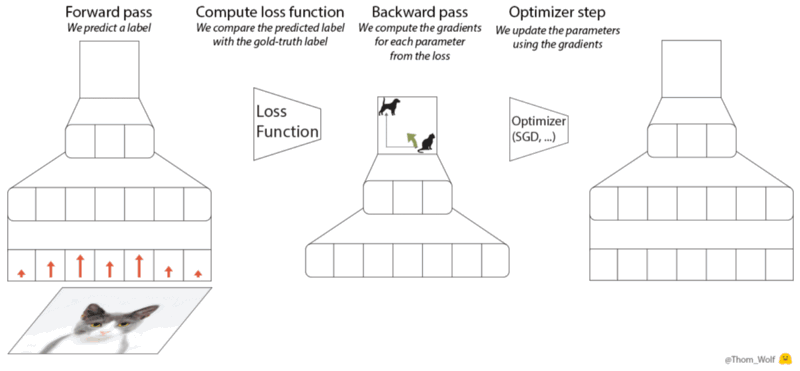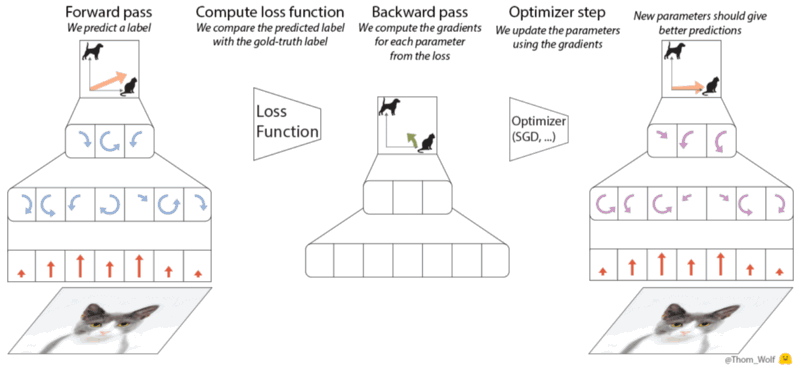 |
|---|
| The 5-steps of a gradient descent optimization algorithm - source |
In 5 lines this training loop in PyTorch looks like this:
def train(train_dl, model, epochs, optimizer, loss_func):
for _ in range(epochs):
model.train()
for xb, yb in train_dl:
out = model(xb)
loss = loss_func(out, yb)
loss.backward()
optimizer.step()
optimizer.zero_grad()Note if we don’t zero the gradients, then in the next iteration when we do a backward pass they will be added to the current gradients. This is because pytorch may use multiple sources to calculate the gradients and the way it combines them is throught a
sum.
For some cases, one may want to do more to control the training loop. For instance, try different:
- regularization techniques
- hyperparameter schedules
- mixed precision training
- tracking metrics
For each case, you end up rewriting the basic loop and adding logic to accomodate these requirements. One way to enable endless possibilities to customize the training loop is to use Callbacks. A callback is very common design pattern in many programming languages, with a basic idea of registering a handler that will be invoked on a sepecific condition. A typical case, will be an handler for specificc errors that may be triggered when calling a remote service.
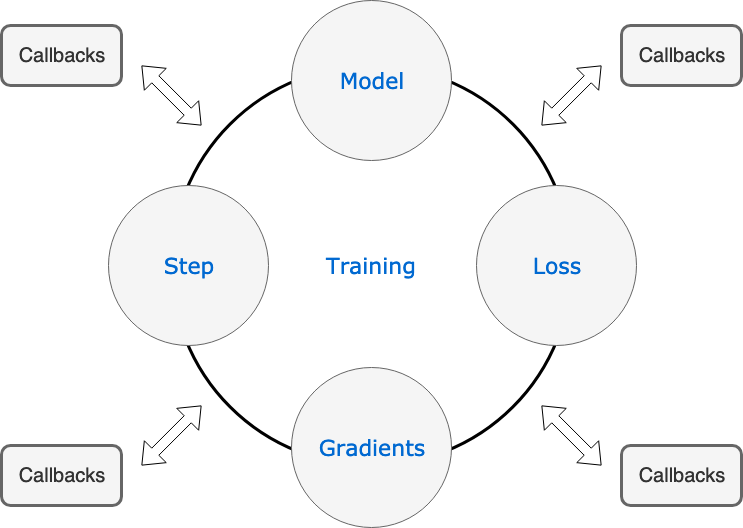
For the use in a training loop, the possible events that we may one have handlers for include when the training begins or ends, and epoch begins or ends, etc. Those handlers can return any useful information or flags that skip steps or stop the trainig.
The Callback interface may looks like this:
def Callback():
def __init__(self): pass
def on_train_begin(self): pass
def on_train_end(self): pass
def on_epoch_begin(self): pass
def on_epoch_end(self): pass
def on_batch_begin(self): pass
def on_batch_end(self): pass
def on_loss_begin(self): pass
def on_loss_end(self): pass
def on_step_begin(self): pass
def on_step_end(self): passNow after adding calback on each life cycle of the training loop, the earlier training loop becomes:
def train(train_dl, model, epochs, optimizer, loss_func, callback):
callback.on_train_begin(...) // training begin event
for epoch in range(epoch):
model.train()
skip = callback.on_epoch_begin(...) // epoch begin event
for xb, yb in train_dl:
skip = callback.on_batch_begin(...) // batch begin event
out = model(xb)
loss = loss_func(out, yb)
skip = callback.on_loss_end(...) // loss calculated end event
if not skip: loss.backward()
skip = callback.on_step_begin(...) // optimizer step begin event
optimizer.step()
skip = callback.on_step_end(...) // optimizer step end event
optimizer.zero_grad()
skip = callback.on_batch_end(...) // optimizer step end event
skip = callback.on_epoch_end(...) // epoch end event
callback.on_train_end(...) // epoch training eventA basic use of callbacks is to log losses and metrics (e.g. accuracy) on the training/validation datasets after each epoch. More advanced use of callbacks can be to actively act on the training by tweaking hyper parameters of the training loop (e.g. learning rates). Furthermore, every tweak can be written in its own callback examples. For instance:
learning rate scheduler
Over the curse of the training, adjusting the learning rate is a practical way to speedup with convergence of the weights to their optimal values and thus requiring less epochs (which has the benefit of avoiding overfitting). There are different ways to schedule learning rate adjustment, time-based decay, step decay and exponential decay. All of which can be implemented with callback, for instance before each mini-batch:
class LearningRateScheduler(Callback):
def on_batch_begin(self, iteration, **kwargs):
# control the learning rate over iteration
self.optimizer.lr = fct(iteration)early stopping
Early stopping aims to let the model be trained as far as a target metric is improving (e.g. accuracy on validation set) and stop otherwise in order to avoid overfitting on the training dataset. Using a callback, we can decide wether to continue training after each epoch or not as follows:
class EarlyStopping(Callback):
def on_epoch_end(self, last_metrics, **kwargs):
# if the monitored metrics got worst set a flag to stop training
if some_fct(last_metrics): return {'stop_training': True}parallel training
Use PyTorch support for multi-GPUs, example
class ParallelTrainer(Callback):
_order = -20
def on_train_begin(self, **kwargs):
self.model = DataParallel(self.model)
def on_train_end(self, **kwargs):
self.model = self.model.modulegradient clipping
Gradient clipping allows the use of a large learning rate ( \(lr=1\) ), see discussion. It can be done by safely modifying Variable.grad.data in place after the backward pass had finished, see example.
class GradientClipping(Callback):
def __init__(self, model, clip=0.):
self.model, self.clip = model, clip
def on_backward_end(self, **kwargs):
if self.clip:
nn.utils.clip_grad_norm(self.model.parameters(), self.clip)accumulating gradient
The basic idea behind accumulating gradient is to sum (or avergage) the gradients of several consecutive backward passes (if they were not reset with model.zero_grad() or optimizer.zero_grad()). This can be straightfully implemented in handler for loss calculated event:
class AccumulateScheduler(Callback):
"""Does accumulated step every nth step by accumulating gradients"""
def __init__(self, model, optimizer, accumulation_steps=1, drop_last=False):
self.model, self.optimizer = model, optimizer
self.accumulation_steps, self.drop_last = accumulation_steps, drop_last
def on_epoch_begin(self, **kwargs):
"""Init samples and batches"""
self.acc_samples, self.acc_batches = 0., 0.
def on_batch_begin(self, last_input, last_target, **kwargs):
"""Accumulate samples and batches"""
self.acc_samples += last_input.shape[0]
self.acc_batches += 1
def on_backward_end(self, **kwargs):
"""Accumulated step and reset samples"""
if self.acc_batches % self.accumulation_steps != 0: return {'skip_step': True, 'skip_zero': True}
for p in self.model.parameters():
if p.requires_grad:
p.grad.div_(self.acc_samples)
self.acc_samples = 0
def on_epoch_end(self, **kwargs):
"""Step the rest of the accumulated grads if not perfectly divisible"""
for p in self.model.parameters():
if p.requires_grad:
p.grad.div_(self.acc_samples)
if not self.drop_last:
self.optimizer.setp()
self.optimizer.zero_grad()Conclusion
Callbacks are a very handy way to experiment techniques to traing larger model (with 100 millions parameters), larger batch sizes and bigger learning rate, but also to fight overfitting and make the model generalizable. A well-designed callback system is crucial and has many benefits:
- keep training loop as simple as possible
- keep each tweak independent
- easily mix and match, or perform ablation studies
- easily add new experiments
- simple for contributors to add their own
However, a mis use of callbacks can turn into a nightmare called callback hell.
Reference - link