
Integrating Elasticsearch with AI agents through Model Context Protocol
18 May 2025 by dzlabLarge Language Models (LLMs) are getting better every day at understanding all sorts of data, but they still suffer from knowledge cut-off when dealing with data that were not part of their pre-training. By integrating LLMs with external systems and knowledge bases, LLMs could achieve their true potential as they allow users to query and analyze complex data with natural conversations. Model Context Protol (MCP) is one way of enable LLMs and AI assistants like Claude Desktop to perform actions, query data, and leverage the capabilities of other applications.
In this blog post, we explore how to implement in Python using the fastmcp library an MCP server for Elasticsearch that enables Claude Desktop (or any AI Agent) to directly query and analyze data from an Elasticsearch cluster. We’ll then see how to configure Claude Desktop to use this server. Full source code can be found at GitHub.
What is MCP?
The Model Context Protocol (MCP) is a standardized interface that allows LLMs like Claude to interact with external systems. It creates a bridge between AI assistants and various data stores, tools, and services while maintaining a consistent communication pattern.
As shown in the diagram, MCP enables a standardized way for AI applications to interact with:
- Data stores (databases, NoSQL databases)
- CRM systems
- Version control software
- And potentially any external service with an appropriate MCP server

Furthermore, using the MCP Approach to integreate AI agents with externalo systems has the following benefits:
- Standardization: MCP provides a consistent interface for LLMs and AI agent to interact with external systems.
- Separation of Concerns: The LLM focuses on understanding and generating responses, while the MCP server handles the specifics of interacting with the target system (in this case, Elasticsearch).
- Security: Authentication details are managed by the MCP server, not exposed to the model.
- Extensibility: New tools can be easily added to the MCP server without changing the core integration.
Building an MCP Server
In this section we will build an MCP server for Elasticsearch
Prerequisites
Before you start, make sure you have:
- An Elasticsearch cluster accessible (either locally or remotely).
- Python installed (
3.8+ recommended). uvfor installing Python packages.- Claude Desktop installed.
Setup
We need to set up the environment that we will use to run our MCP server. We will use the uv tool, which helps manage Python environments, it automatically sets up the project files and manages the package dependencies.
In the project directory (e.g. elasticsearch_mcp), initialize a uv project:
uv init
uv venv
source .venv/bin/activate
The add the needed Python dependencies:
uv add elasticsearch
uv add python-dotenv
uv add mcp
Connecting to Elasticsearch
Our MCP server needs to connect to the Elasticsearch cluster. We’ll use environment variables to pass connection information and store them in a .env file. Here are few examples of content with different authentication methods:
Environment variables for API Key authentication
# .env
ES_URL=http://localhost:9200
ES_API_KEY=your_base64_encoded_api_key
ES_CA_CERT=/path/to/http_ca.crt # Optional, for HTTPS verification
Environment variables for Basic Auth authentication
# .env
ES_URL=http://localhost:9200
ES_USERNAME=your_username
ES_PASSWORD=your_password
ES_CA_CERT=/path/to/http_ca.crt # Optional, for HTTPS verification
Next, in our python code we load environment variables from .env and then create an Elasticsearch client instance with one of the following authentication methods:
- API key authentication
- Username/password authentication
- No authentication for local development
# server.py
from elasticsearch import Elasticsearch
from dotenv import load_dotenv
load_dotenv()
def createElasticsearchClient():
# Access environment variables
ES_URL = os.getenv('ES_URL')
ES_API_KEY = os.getenv('ES_API_KEY') # base64 encoded api key
ES_USERNAME = os.getenv('ES_USERNAME')
ES_PASSWORD = os.getenv('ES_PASSWORD')
ES_CA_CERT = os.getenv('ES_CA_CERT') # path to http_ca.crt file # Optional, for HTTPS verification
if ES_API_KEY:
return Elasticsearch(hosts=[ES_URL], api_key=ES_API_KEY, ca_certs=ES_CA_CERT)
if ES_USERNAME and ES_PASSWORD:
return Elasticsearch(hosts=[ES_URL], basic_auth=(ES_USERNAME, ES_PASSWORD), ca_certs=ES_CA_CERT)
return Elasticsearch(hosts=[ES_URL])
es = createElasticsearchClient()
Exposing Tools
Now, let’s define the functions that will interact with the Elasticsearch and serve as our MCP tools.
First, we create an MCP server instance that allows Claude Desktop to interact with an Elasticsearch cluster:
# server.py
from mcp.server.fastmcp import FastMCP
mcp = FastMCP("elasticsearch-mcp-server")
Next, we define our main functions to list indices, get mappings, and perform searches. And annotate them with the @mcp.tool() decorator to register these Python functions as available tools for the MCP server.
1. List Indices
A function allowing Claude to retrieve all available indices in the Elasticsearch cluster.
# server.py
@mcp.tool()
def list_indices() -> List[str]:
"""
List all available Elasticsearch indices.
Returns:
List of indices
"""
indices = es.indices.get_alias(index="*")
index_names = list(indices.keys())
return index_names
2. Get Mappings
A function to enable Claude to understand the structure of data within a specific index by retrieving its mapping schema.
# server.py
@mcp.tool()
def get_mappings(index: str) -> dict:
"""
Get field mappings for a specific Elasticsearch index.
Args:
index: Name of the Elasticsearch index to get mappings for
Returns:
Mapping schema for the specified index
"""
mappings = es.indices.get_mapping(index=index)
return mappings
3. Search
A function to allow Claude to execute Elasticsearch queries using the full power of the Elasticsearch Query DSL.
# server.py
@mcp.tool()
def search(index: str, queryBody: dict) -> dict:
"""
Perform an Elasticsearch search with the provided query DSL. Highlights are always enabled.
Args:
index: Name of the Elasticsearch index to search
queryBody: Complete Elasticsearch query DSL object that can include query, size, from, sort, etc.
Returns:
Search result
"""
response = es.search(index=index, body=queryBody)
return response
Using our MCP server
Our MCP server can be used by any AI assistant/IDE that supports MCP, including Claude Desktop.
Configuring Claude Desktop
For Claude Deskto to connect to our Elasticsearch MCP server, we need to register the MCP server by adding it to Claude configuration file named claude_desktop_config.json. In MacOS, it should be available at ~/Library/Application\ Support/Claude/.
The configuration for our Elasticsearch MCP server should look like this:
{
"mcpServers": {
"ElasticsearchServer": {
"command": "/path/to/uv",
"args": [
"--directory",
"/path/to/elasticsearch_mcp",
"run",
"server.py"
]
}
}
}
This configuration tells Claude Desktop how to launch the Elasticsearch MCP server:
- It uses
uv(a Python package manager/runner) to execute the server - It specifies the working directory where the server code is located
- It runs the
server.pyscript
After editing the config file, restart Claude Desktop app and check that the new MCP server connected was connected successfully as illustrated in the following screenshot:
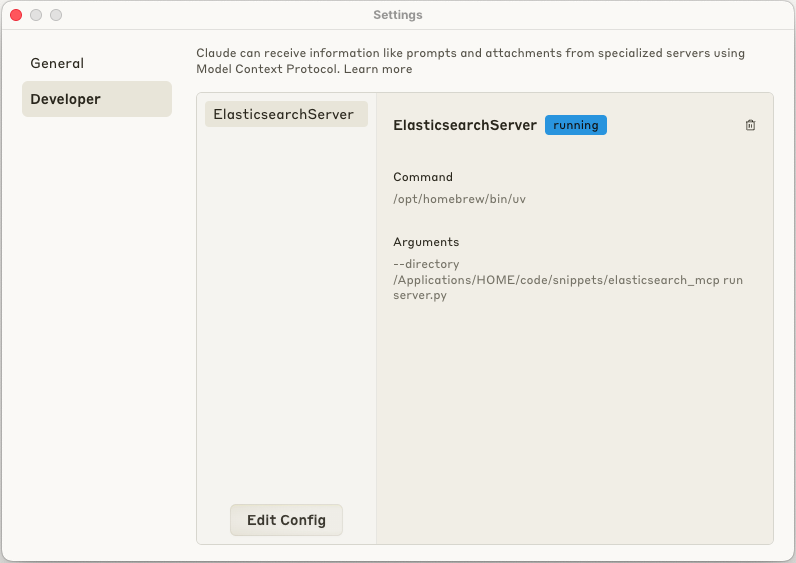
If case of connection issues, you can check the logs of the MCP server
tail -n 20 -f ~/Library/Logs/Claude/mcp-server-ElasticsearchServer.log
Using the Elasticsearch MCP Server with Claude
With our MCP server implemented and Claude Desktop configured, we can now interact with our Elasticsearch cluster directly from Claude. For this, simply launch Claude Desktop and start a new conversation, that’s it.
We can ask Claude questions about our Elasticsearch cluster and it will use the list_indices, get_mappings, or search tools accordingly to fulfill the requests.
Here are few questions and answers:
1. What are the indices available in my Elasticsearch cluster?
I'll check what Elasticsearch indices are available in your cluster right now.
I can see that there is one index available in your Elasticsearch cluster:
- `hacker_news_posts`
Would you like me to explore this index further, such as checking its mapping schema or running some sample queries?
2. what are the mappings for the ‘hacker_news_posts’ index?
I'll retrieve the mappings for the 'hacker_news_posts' index to show you its structure.
Here are the mappings for the 'hacker_news_posts' index:
### Top-level fields:
- `by`: text field with keyword sub-field (for exact matching)
- `id`: long (numeric) field
- `score`: long (numeric) field
- `time`: long (numeric) field, likely represents timestamps
- `title`: text field with keyword sub-field
- `type`: text field with keyword sub-field
- `url`: text field with keyword sub-field
### Nested comments structure:
- `comments`: object with the following properties:
- `id`: text field with keyword sub-field
- `level`: long (numeric) field
- `parent_id`: text field with keyword sub-field
- `text`: text field with keyword sub-field
- `time_ago`: text field with keyword sub-field
- `user`: text field with keyword sub-field
This appears to be an index storing Hacker News posts along with their associated comments. Each post has standard metadata like author (`by`), post ID, score, timestamp, title, type, and URL. The comments are stored as nested objects with their own structure including comment ID, nesting level, parent comment ID, comment text, relative time posted, and user who posted the comment.
Would you like me to show you how to query this data in a specific way?
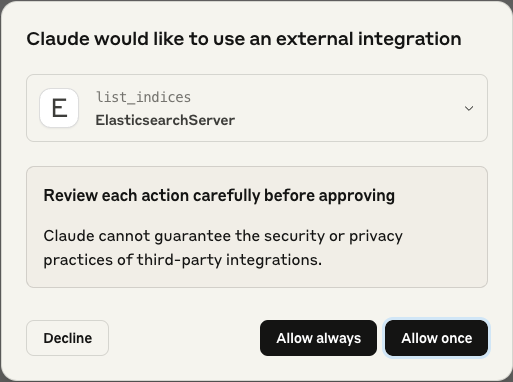
Notes: Claude Desktop will ask confirmation before using external tools as illustrated below
Conclusion
We have successfully built a basic Elasticsearch MCP server using fastmcp and integrated it with Claude Desktop. This allowed us to query and explore data from Elasticsearch using natural language within Claude.
Also note that Claude already provides a plethora of MCP servers that it can combine to let the user perform various tasks with simple natural language:
- Data exploration and analysis
- Generating insights from large datasets
- Creating visualizations based on query results
- Answering complex questions about data stored in Elasticsearch
The standardization that MCP brings to AI development promises to make integrations more consistent, reliable, and easier to maintain as the AI ecosystem continues to evolve. By following the MCP pattern, you can create similar integrations for various data sources and services, expanding the capabilities of AI assistants like Claude without needing to modify the core LLM itself.
That’s all folks
I hope you enjoyed this article, feel free to leave a comment or reach out on twitter @bachiirc.