
Spark on Kubernetes the Operator way - part 1
14 Jul 2020 by dzlab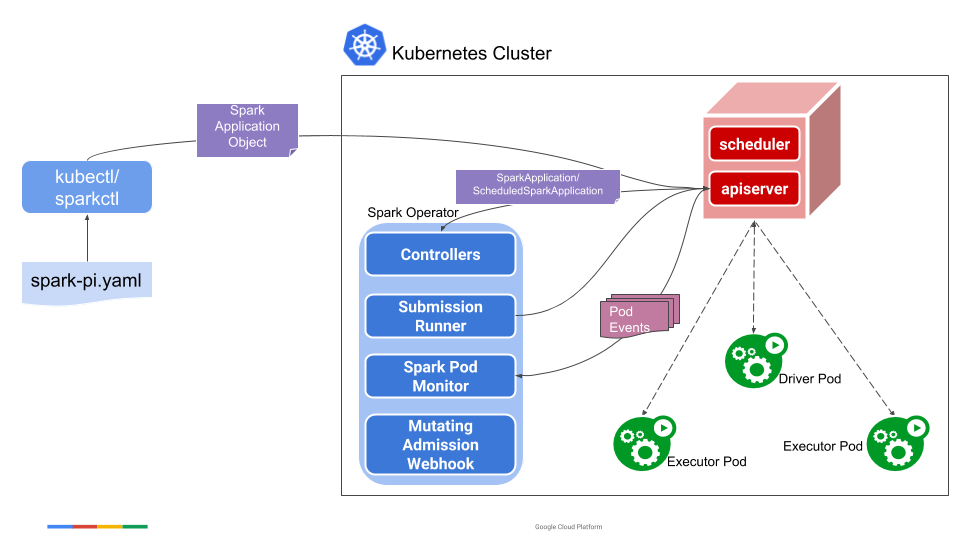
Spark Operator is an open source Kubernetes Operator that makes deploying Spark applications on Kubernetes a lot easier compared to the vanilla spark-submit script.
One of the main advantages of using this Operator is that Spark application configs are writting in one place through a YAML file (along with configmaps, volumes, etc.). Furthermore, Spark app management becomes a lot easier as the operator comes with tooling for starting/killing and secheduling apps and logs capturing.
The rest of this post walkthrough how to package/submit a Spark application through this Operator. For details on how to use spark-submit to submit spark applications see Spark 3.0 Monitoring with Prometheus in Kubernetes.
As of the day this article is written, Spark Operator does not support Spark 3.0
1- Setup a kubernetes cluster
for instance using minikube with Docker’s hyperkit (which way faster than with VirtualBox).
$ minikube start --driver=hyperkit --memory 8192 --cpus 4
2- Create kubernetes objects
Before installing the Operator, we need to prepare the following objects:
- A Namespace for the Operator itself.
- A Namespace for the Spark applications, it will host both driver and executor pods.
- A ServiceAccount for the Spark applications pods.
- A RoleBinding to associate the previous ServiceAccount with minimum permissions to operate. Here we give it an edit cluster-level role.
The spark-operator.yaml file summaries those objects in the following content:
We can apply this manifest to create everything needed as follows:
$ kubectl create -f spark-operator.yaml
namespace/spark-operator created
namespace/spark-apps created
serviceaccount/spark created
clusterrolebinding.rbac.authorization.k8s.io/spark-operator-role created
3- Install Spark Operator
The Spark Operator can be easily installed with Helm 3 as follows:
$ # Add the repository where the operator is located
$ helm repo add incubator http://storage.googleapis.com/kubernetes-charts-incubator
"incubator" has been added to your repositories
$ # Install the operator with helm
$ helm install sparkoperator incubator/sparkoperator --namespace spark-operator --set sparkJobNamespace=spark-apps,enableWebhook=true
NAME: sparkoperator
LAST DEPLOYED: Mon Jul 13 19:38:37 2020
NAMESPACE: spark-operator
STATUS: deployed
REVISION: 1
TEST SUITE: None
Check the status of the operator
$ helm status sparkoperator -n spark-operator
NAME: sparkoperator
LAST DEPLOYED: Mon Jul 13 19:38:37 2020
NAMESPACE: spark-operator
STATUS: deployed
REVISION: 1
TEST SUITE: None
With minikube dashboard you can check the objects created in both namespaces spark-operator and spark-apps.
4- Submit Spark job
To make sure the infrastructure is setup correctly, we can submit a sample Spark pi applications defined in the following spark-pi.yaml file.
This file describes a SparkApplication object, which is obviously not a core Kubernetes object but one that the previously installed Spark Operator know how to interepret.
- It specify the base image to use for running Spark containers
gcr.io/spark-operator/spark:v2.4.5 - A location of the application jar within this Docker image
- The main class to be invoked and which is available in the application jar.
- The Driver pod information: cores, memory and service account
- The Executors information: number of instances, cores, memory, etc.
Now we can submit a Spark application by simply applying this manifest files as follows:
$ kubectl apply -f spark-pi.yaml
sparkapplication.sparkoperator.k8s.io/spark-pi created
This will create a Spark job in the spark-apps namespace we previously created, we can get information of this application as well as logs with kubectl describe as follows:
$ kubectl describe SparkApplication spark-pi -n spark-apps
Now the next steps is to build own Docker image using as base gcr.io/spark-operator/spark:v2.4.5, define a manifest file that describes the drivers/executors and submit it.