
TensorFlow Distributed Training on Kubeflow
18 Jul 2020 by dzlab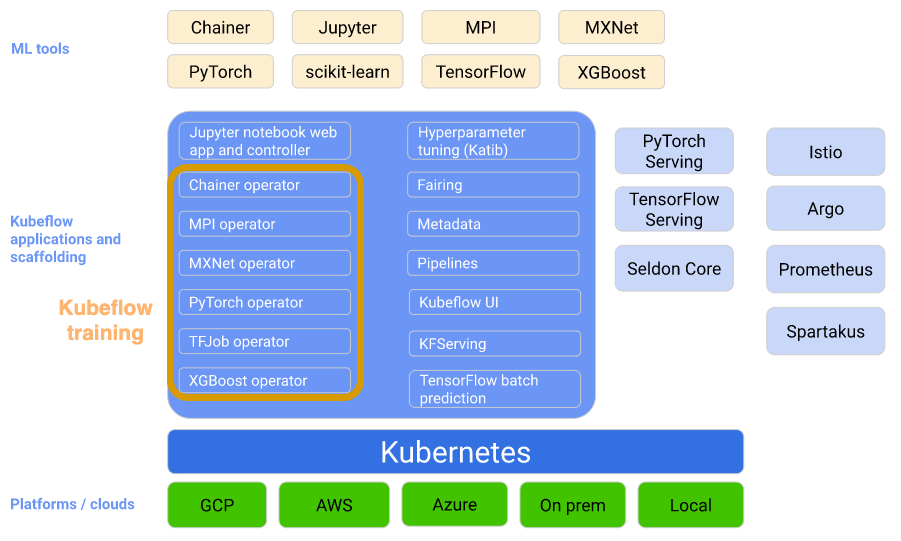
Overview
Deep learning models are getting larger and larger (over 130 billion parameters) and requires more and more data for training in order to achieve higher performance.
Training such models is not possible on one machine, but rather requires a fleet of machines. Distributed training aims to provide answers to this problem with the following possible approaches.
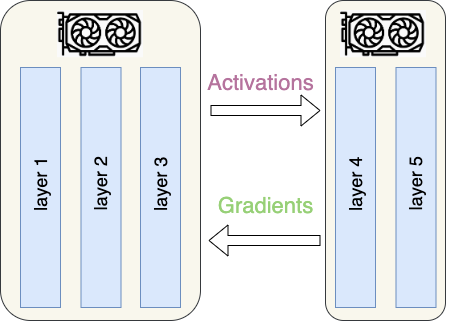
Model Parallelism
In Model Parallelism, the model parameters are distributed across multiple machines as it does not fit on a single one. Each worker will be responsible on updating the parameters is responsible for with a forward and backward passes. In this paradigm, a worker communicates with the subset of works that hold the layers it depends on during the forward pass and those that depend on during the backward pass.
Data Parallelism
In Data Parallelism, each worker host the whole model but is given a subset of the data which is potentially different from the one given to another worker. In this paradigm, there is no need for workers to communicate with each other, but rather a central worker (usually called a Parameter Server) is responsible for:
- aggregating the losses it receives from every workers’ forward pass and
- replying back to the workers with the updated weights.
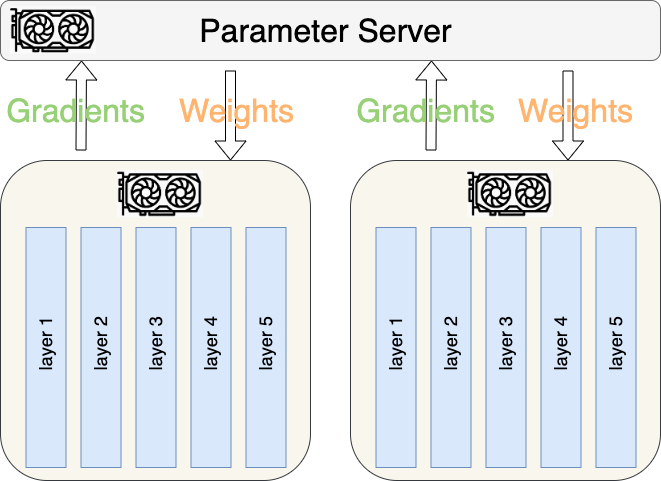
In TensorFlow for instance, one could train a model with the Data Parallelism paradigm easily as illustrated in the following snippet
strategy = tf.distribute.MirroredStrategy()
with strategy.scope():
model = tf.keras.Sequential([
tf.keras.layers.Conv2D(32, 3, activation='relu', input_shape=(28, 28, 1)),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dense(10, activation='sotfmax')
])
model.compile(loss='sparse_categorical_crossentropy', optimizer=tf.keras.optimizers.Adam())
Distributed Training in Kubeflow
The Kubeflow project is a complex project that aims at simpliying the provisioning of a Machine Learning infrastructure. It is built on top of Kubernetes and thus reuses k8s core components (pods, services, etc.) and adapt them for the ML use cases.
Kubeflow training is a group Kubernetes Operators that add to Kubeflow support for distributed training of Machine Learning models using different frameworks, the current release supports:
- TensorFlow through tf-operator (also know as TFJob)
- PyTorch through pytorch-operator
- Apache MXNet through mxnet-operator
- MPI through mpi-operator
See https://www.kubeflow.org/docs/components/training/ for more details.
Rest of this post, we will use:
- Docker Hub to host a tensorflow-based container image that contains the model training logic.
- TFJob to describe the processes that will run the training in a distributed fashion.
Create a training image
Create a repo on Docker Hub called tf-dist-mnist-test and login locally with docker login
Clone the Kubeflow tf-operator project and navigate to the mnist example
$ git clone https://github.com/kubeflow/tf-operator
$ cd tf-operator/examples/v1/dist-mnist
Build the mnist locally
$ docker build -f Dockerfile -t <DOCKER_HUB_USERNAME>/tf-dist-mnist-test:1.0 ./
Push the image you just built to Docker Hub
$ docker push <DOCKER_HUB_USERNAME>/tf-dist-mnist-test:1.0
The push refers to repository [docker.io/<DOCKER_HUB_USERNAME>/tf-dist-mnist-test]
3d980aca20f2: Pushed
c04a36d9e118: Pushed
d964bb768e1a: Pushed
db582379df14: Pushed
5bb39b263596: Pushed
02efdb75efd8: Pushed
dee07873361c: Pushed
0b029684a0e5: Pushed
6f4ce6b88849: Pushed
92914665e7f6: Pushed
c98ef191df4b: Pushed
9c7183e0ea88: Pushed
ff986b10a018: Pushed
1.0: digest: sha256:28fe6870f37380b065f7cda1d71f9401709c5a2c7d0dca55563cbd1b14d18911 size: 3038
Submit training job
A TFJob is a resource with a YAML representation like the one below: (before submitting your job relpace <DOCKER_HUB_USERNAME> with your Docker Hub username)
Each tfReplicaSpecs defines a set of TensorFlow processes. Under this spec we define different types of processes, a PS (Parameter Server) and Workers with their respective replication factor and container image.
Submit TFJob distributed training job
$ kubectl apply -f mnist-tensorflow-job.yaml
tfjob.kubeflow.org/mnist-tensorflow-job created
Get all TFJob resources which were previously created:
$ kubectl get tfjob
NAME STATE AGE
mnist-tensorflow-job Succeeded 3m26s
Check the status of a speific TFJob resource:
$ kubectl describe tfjob mnist-tensorflow-job
The output may look like below.
Notice that some of the pods were already deleted, in the YAML manifest we set the number of workers to 2 plus a PS (Parameter Server)
Check all the pods created by this TFJob
$ kubectl get pod | grep mnist-tensorflow-job
mnist-tensorflow-job-worker-0 0/1 Completed 0 5m43s
To get the logs of any of this TFJob pods use the following command:
$ kubectl get logs mnist-tensorflow-job-worker-0
The next steps would be to actually create own TensorFlow training logic, package the container image as described in this post and submit the job.