
GPT-3 An Overview
25 Jul 2020 by dzlabGPT-3 is the last brain child of OpenAI in an attempt to demostrate that scalling-up language models improves drastically their task-agnostic performance. To answer this question:
- they trained 8 different models with same architecture but different sizes,
- they trained on a huge dataset (300 billion tokens) that combines different text sources
- they cleaned training dataset to sample only high quality documents
The only technical document that describes GPT-3 is the 72-page-long report available on arxiv - link. Neither the code nor any of the pre-trained models where published as of today. This article is an attempt to demystify GPT-3.
Data
To avoid overfitting of the training dataset, at the scale of a Neural Netowrk with hundreds billion parameters, the data to use for training have to be as well huge. This raises several new type of problems that need to be addressed so that the training goes well.
- There is no high quality curated dataset to use as for training and such dataset have to be created.
- The other problem is the super high risk of the evaluation dataset to contain data seen during the training. In the paper this is refered as Data Contamination.
Improving data quality
The training dataset is heavily based on the Common Crawl dataset (with 410 billion tokens), to improve its quality they performed the following steps (which are summarized in the following diagram):

Filtering
They downloaded and filtered a version of CommonCrawl based on similarity to a range of high-quality reference corpora. They developed an automatic filtering method that relies on the original WebText dataset (which was used to train GPT-2, a clone version can be found here https://github.com/jcpeterson/openwebtext) as a proxy for high-quality documents.
They trained a logistic regression classifier to distinguish the curated datasets (WebText, Wikiedia and the book corpus) which represents the positive examples from raw unfiltered Common Crawl representing negative examples. For this classification task, they generated features from each document using Spark’s standard tokenizer and HashingTF.
Once the classifier is trained, it is used for sampling documents from the raw Common Crawl in a way that prioritized those documents that the classifier gave a high quality score. A document from Common Crawl dataset is kept if it satisfies the following constraint: \(np.random.pareto(\alpha) > 1 − document\_score\)
For clarity, the Pareto distribution looks like the following:
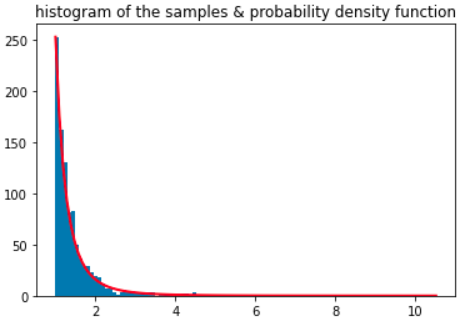
Deduplication
To improve quality and prevent overfitting, a fuzzy deduplication was performed at the document level to remove highly overlapping documents. Based on the document features generated by the previous classification step, a Spark’s MinHashLSH (which is a Spark implementation of Locality Sensitive Hashing (LSH)) with 10 buckets so that documents which are very similar will end up in the same bucket. This step drastically reduced the size of the dataset by 10%.
Mixing
Finally, to augment the resulting CommonCrawl from the previous step, other high-quality datasets (WebText, books corpora, English-language Wikipedia documents) were added to form the final training dataset mix to augment CommonCrawl and increase its diversity.
Preventing data contamination
Due to the high chance of overlap between development and test dataset as both where sourced from the internet, the test dataset had to be cleaned and remove any such overlaps from the test dataset.
Model
GPT-3 has the same attention-based architecture as GPT-2, see below screenshot taken from the original GPT-2 paper.
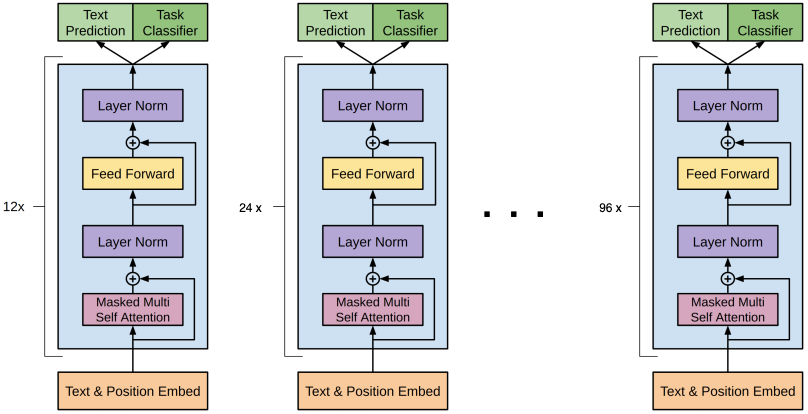
The main difference between the two models are the number of layers. In the paper, they used a range of model sizes between 125M and up to 175B (the real GPT-3). The smallest (i.e. 125M) has 12 attention layers, with each one having 12 heads, and each one of them is of 64 dimensions. The biggest one in the other hand, is 96 attention layers, with 96 attention heads, and 128 dimensions. The following screenshot taken from the paper summarizes the architectures.
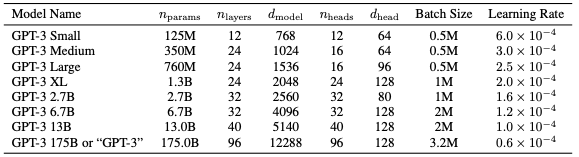
- \(n_{params}\): number of trainable parameters
- \(n_{layers}\): number of attention layers
- \(d_{model}\): number of units in each bottleneck layer
- \(n_{head}\): dimension of each attention head
- \(n_{ctx}\): context window which is fixed for all models to 2048
Training
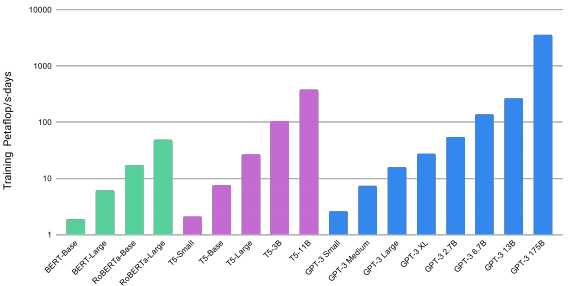
The original paper does not provide any technical details about the training of the eight different GPT-3 models. This makes someone wonder what is the specific training settings and infrastrucutre required to train such huge model. But looking at the computation cost (see following screenshot which was taken from the paper) it is clear that doing 3.64E+03 Peta FlOps a day (total compute for training GPT-3) would require a lot on a lot of V100 instances.
The other challenge is the size of the model that cannot not fit into the memory of one single GPU but require a cluster of them. With 175 Billion parameters and assuming each one of them take 4 bytes would be 175 Billion * 4 Bytes = 700 GB.
The two challenges requires splitting the model intelligently, but the only description provided in the paper about this is vague description of model parallelism
We partition the model across GPUs along both the depth and width dimension in order to minimize data-transfer between nodes.
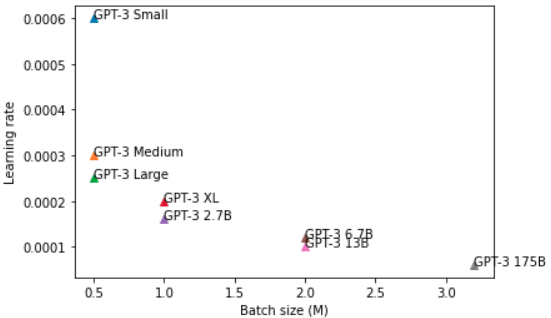
For the hyper parameters, for each one of the eight models a different range of hyper-parameters was used. For instance, for the 125M version of GPT-3 a batch size of 0.5M and learning rate of 0.0006 was used, as the model gets bigger the batch size was increased and the learning rate was decreased. The biggest verion of GPT-3 with 175B params used a batch size of 3.2M and learning rate of 0.00006. The following charts illustrates the combination of those hyper-params per model.
In-Context learning
This is where the family of GPT models stand out unlike other language models (transformer-based or not) that need a fine-tuning step in order to be perform well on a downstream tasks. i.e., if you would need to BERT to do sentiment classification or QA you would need to fine tuned on your dataset as well as replacing the head of the model. GPT and especially GPT-3 does not work like that as it is capable of using the same model to perform well on any downstream task without fine-tuning. Although, for the evaluation of the model different settings were used in order to see how mush task-specific data each of the GPT-3 model versions would require.
- Fine-tuning the most common approach, it involves updating the model parameters by further training the model in a supervised manner on the dataset of the new task at hand. This usually requires a dataset of hundreds of thousands of labeled data.
- Few-shots the model is given a few demonstrations of the task at inference time as. This does not involve any updates to the model parameters. The dataset in this case contains a context and between 10 to 100 examples (enlish to french pair of translated sentences).
- One-shot: same as Few-shots except that only one example is given to the model at inference.
- Zero-shot similar to the previous two execpt that no examples are given to the model rather a natural language description of the task is given to the model. This is GPT-3, pretty neat no?
The following table illustrates how the different variation of XYZ-Shots is used at inference (the examples were taken from the paper):
| Few-shots | One-shot | Zero-shot | |
|---|---|---|---|
| task description | Translate English to French | Translate English to French | Translate English to French |
| examples | sea otter => loutre de mer perppermint => menthe poivrée plush girafe => girafe peluche |
sea otter => loutre de mer | |
| prompt | cheese => | cheese => | cheese => |
Take aways
The following are few take aways from the GPT-3 paper:
- It shows that language models perform better as they scale in size of model, dataset, and computation.
- It demonstrates that a language model trained on enough data can solve tasks not seen before.
- Its not your bag of tricks but the size of the model that achieves state-of-the-art (SOTA).
- Fewer can afford the cost of training such models as the cost gets overwhelming high.
- As models get bigger outpacing the growth of GPUs model parallelization becomes indispensable.