
End to End ML pipelines with MLflow Projects
09 Aug 2020 by dzlabMLflow is an open-source project to make the lifecycle of Machine Learning projects a lot easier with capabilities for experiment tracking, workflow management, and model deployment.

It provides four components that can be leveraged to manage the lifecycle of any ML project. They are:
-
MLflow Tracking it is an API for logging parameters, versioning models, tracking metrics, and storing artifacts (e.g. serialized model) generated during the ML project lifecycle.
-
MLflow Projects it is an MLflow format/convention for packaging Machine Learning code in a reusable and reproducible way. It allows a Machine Learning code to be decomposed into small chunks that address very specific use cases (e.g. data loading/processing, model training, etc.) and then chaining them together to form the final machine learning workflow.
-
MLflow Models it is an MLflow packaging convention for models so that they can be reused later (e.g. further training). Typical usage will be model serving for batch inference with Spark or real time inference with a REST endpoint.
-
Model Registry it is a centralized store for managing the lifecycle of an MLflow Model (e.g. storing model, promoting model to production or archiving the model). It captures metadata about the full lifecycle to provides model lineage: which MLflow experiment produced a given model, who transitioned the model from staging to production, etc.
Those components can be accessed through REST calls or by using one of the supported SDKs (Python, R, Java). It also provides a web interface for visualizing what was generated by the machine learning project.
 |
| Source: MLflow: Infrastructure for a Complete Machine Learning Life Cycle |
With MLflow, one can build a Pipeline as a multistep workflow by making use of MLflow API for running a step mlflow.projects.run() and tracking within one run mlflow.tracking. This is possible because each call mlflow.projects.run() returns an object that holds information about the current run and can be used to store artifacts. This way, the next step that will be run with mlflow.projects.run() will have access to whatever the previous step had produced.
As an example, assuming that in our ML project we need to download data, process it, and then train a model on it and finally store the trained model. We can organize such a pipeline into different steps and for each one define a python program to perform it:
download.pywill download raw data (e.g. CSV files) and save it into the artifact store.process.pywill process the raw data (e.g. CSV files) produced by the previous step into a more training friendly format, e.g. pickle or TFRecords. It may also perform other data processing tasks like cleaning. The generated data will be put back into the artifact store.train.pywill build a model (e.g. Keras model) and train it on the data produced by the previous task. Once training finishes the model is put in the artifact store for later use, e.g. serving.main.pyis the entry point of the pipeline and will be orchestrating the previous steps.
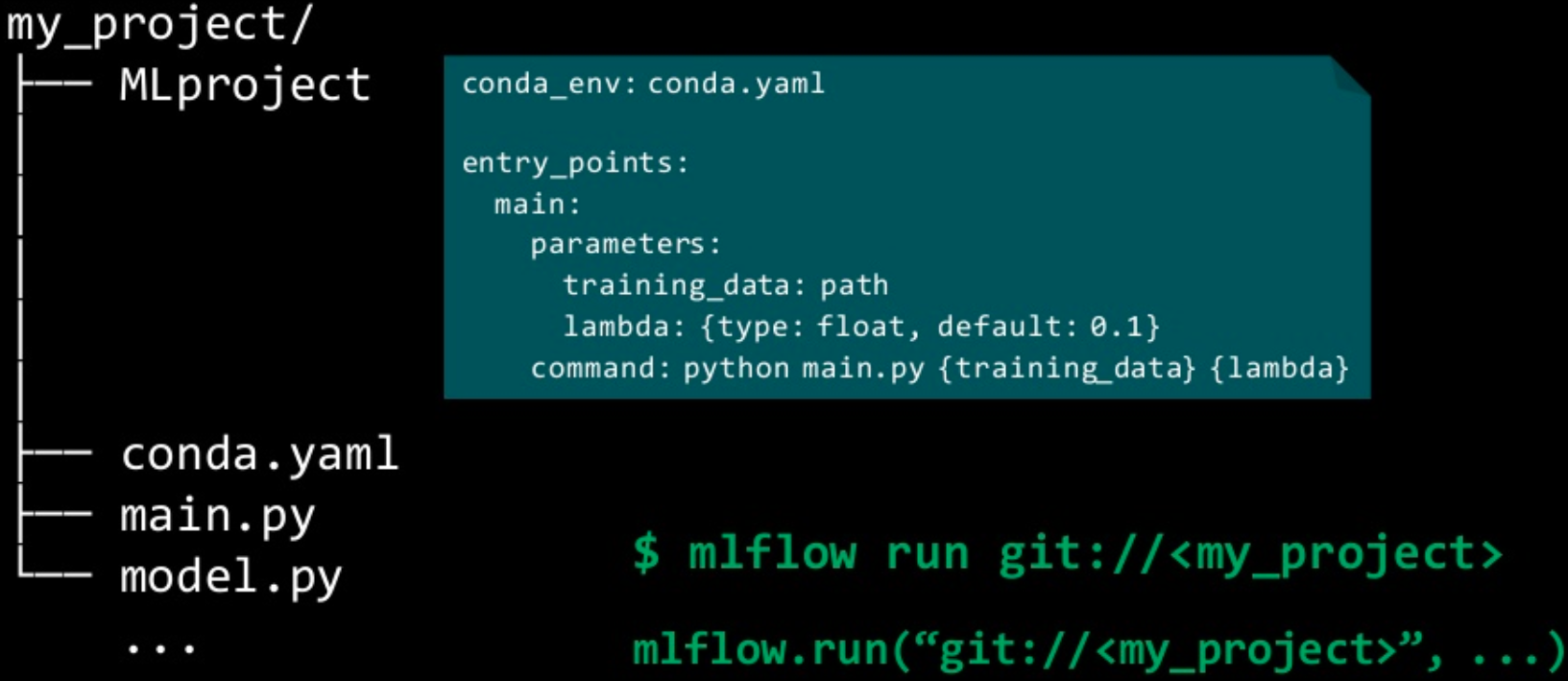
We need to tell MLflow the structure of our project by declaring the steps and the required dependencies through the following YAML files.
MLprojectthis is a special file where each step is declared, how it should be called as well as its inputs. For instance, in our case the file would look like this:
name: multistep
conda_env: conda.yaml
entry_points:
download:
command: "python download.py"
process:
parameters:
file_path: path
command: "python process.py --file-path {file_path}"
train:
parameters:
data_path: path
command: "python train.py --data-path {data_path}"
main:
parameters:
input1: {type: int, default: 1000000}
command: "python main.py --input1 {input1}"
conda.yamlis another special file that can be used to declare the conda environment needed to run the steps in this pipeline.
name: multistep
channels:
- defaults
dependencies:
- python=3.6
- requests
- ...
- pip:
- tensorflow==2.0.0
- mlflow>=1.0
Now we can start implementing the steps, each one with its own file. The following snippet is a template that can be reused for each file to read inputs/write output from/to the artifact store.
#task.py
import mlflow
import click
@click.command(help="This program does ...")
@click.option("--input1")
@click.option("--input2", default=1, help="This is a ...")
def task(input1, input2):
with mlflow.start_run() as mlrun:
# logic of the step goes here
output = ...
print("Uploading output: %s" % output)
mlflow.log_artifacts(output, "output")
if __name__ == '__main__':
task()
Note: click is used here to simplify the parsing of CLI arguments
Finally, the main.py where we orchestrate everything into one worflow:
# main.py
@click.command()
@click.option("--input", default=10, type=int)
def workflow(input):
with mlflow.start_run() as active_run:
print("Launching 'download'")
download_run = mlflow.run(".", "download", parameters={})
download_run = mlflow.tracking.MlflowClient().get_run(download_run.run_id)
file_path_uri = os.path.join(download_run.info.artifact_uri, "file_path")
print("Launching 'process'")
process_run = mlflow.run(".", "process", parameters={"file_path": file_path_uri})
process_run = mlflow.tracking.MlflowClient().get_run(process_run.run_id)
data_path_uri = os.path.join(download_run.info.artifact_uri, "data_path")
print("Launching 'train'")
train_run = mlflow.run(".", "train", parameters={"data_path": data_path_uri})
train_run = mlflow.tracking.MlflowClient().get_run(train_run.run_id)
if __name__ == '__main__':
workflow()
The project structure should look like this:
.
├── MLproject
├── conda.yaml
├── download.py
├── main.py
├── process.py
└── train.py