
Hyperparameter Tuning with MLflow and HyperOpt
16 Aug 2020 by dzlabHyperparameters are parameters that control model training and unlike other parameters (like node weights) they are not learned. Examples of such parameters are the learning rate or the number of layers in a Neural Network.
Choosing the right values for those Hyperparameters is crucial for good training but it is not easy to just guess them. Hyperparameter tuning (or Optimization) is the process of optimizing the hyperparameter to maximize an objective (e.g. model accuracy on validation set). Different approaches can be used for this:
- Grid search which consists of trying all possible values in a set
- Random search which randomly picks values from a range
- Bayesian optimization an iterative approach that tries to choose best values
There are many tools that automate this process given an evaluation/objective function (e.g. maximize accuracy).
The rest of this article explores using HyperOpt with MLflow to find the best hyperparameter to use for training a TensorFlow model.
Hyperparameters Tuning with MLflow
The best practices for organizing runs in MLflow and tracking for hyperparameter tuning looks like this (source):
| Tuning | MLflow runs | MLflow logging |
|---|---|---|
| Hyperparameter tuning algorithm | Parent run | Metadata, e.g., numFolds for CrossValidator |
| Fit & evaluate model with hyperparameter setting #1 | Child run 1 | Hyperparameters #1, evaluation metric #1 |
| Fit & evaluate model with hyperparameter setting #2 | Child run 2 | Hyperparameters #2, evaluation metric #2 |
| … | … | … |
This translates to an MLflow project with the following steps:
traintrain a simple TensorFlow model with one tunable hyperparameter: learning-rate and uses MLflow-Tensorflow integration for auto logging - link.mainperfrom the search, it uses Hyperopt to optimize the hyperparameters but runningtrainset on every setting.
The resulting MLproject file looks like this
# MLproject
name: HyperparameterTF
conda_env: conda.yaml
entry_points:
# Step for model training
train:
parameters:
data: {type: string, default: "./datasets/xyz.csv"}
epochs: {type: int, default: 10}
batch_size: {type: int, default: 32}
learning_rate: {type: float, default: 3e-4}
command: "python train.py {data}
--batch-size {batch_size}
--epochs {epochs}
--learning-rate {learning_rate}"
# Main step for launching hyper-parameters tuning
main:
parameters:
data: {type: string, default: "./datasets/xyz.csv"}
max_runs: {type: int, default: 12}
epochs: {type: int, default: 32}
metric: {type: string, default: "rmse"}
algo: {type: string, default: "tpe.suggest"}
command: "python search.py {training_data}
--max-runs {max_runs}
--epochs {epochs}
--metric {metric}
--algo {algo}"
The conda.yaml file referenced in the MLproject is simply used to declare all the needed dependencies, it may look like this:
# conda.yaml
name: hyperparam_tensorflow
channels:
- defaults
dependencies:
- python=3.6
- numpy=1.14.3
- pandas=0.22.0
- pip:
- mlflow>=1.0
- hyperopt==0.1
- tensorflow==2.0.0
Train step
The train step is implemented by the train.py where the hyperprameters are used to build the model and train it. On a high level, this is what it does:
- Load the input dataset and split it into training and validation sets. The later is used to select the best hyperparameter values.
- Training and validation metrics are logged with MLflow Tracking, they can be inspected in the MLflow UI.
The train.py looks like this:
# train.py
import pandas as pd
import tensorflow as tf
import mlflow.tensorflow
# Enable auto-logging to MLflow
mlflow.tensorflow.autolog()
@click.command(help="Trains a TensorFlow model on CSV input.")
@click.option("--epochs", type=click.INT, default=10, help="Number of train steps.")
@click.option("--batch-size", type=click.INT, default=32, help="Batch size.")
@click.option("--learning-rate", type=click.FLOAT, default=1e-2, help="Learning rate.")
@click.argument("data")
def run(data, epochs, batch_size, learning_rate):
warnings.filterwarnings("ignore")
# Read data and split on train/validation sets
df = pd.read_csv(data)
train, valid = train_test_split(df, random_state=31)
train_x, train_y = ... # separate label and features
valid_x, valid_y = ... # separate label and features
# Build and train the model
with mlflow.start_run():
# build model architecture
model = _create_model()
model.compile(
loss='mean_squared_error',
optimizer=Adam(lr=learning_rate,),
metrics=[]
)
# train model
model.fit(train_x, train_y,
batch_size=batch_size,
epochs=epochs,
validation_data=(valid_x, valid_y),
verbose=1,
callbacks=[])
if __name__ == '__main__':
train()
Main step
In the main step is where most of the interesting stuff happening and the actual best practices described earlier are implemented. On a high level, it does the following:
- Define an objective function that wraps a call to run the
trainstep with the hyperprameters choosen by HyperOpt and returns the validation loss. - Define a search space for all the hyperparameters that need to be optimized.
- Run HyperOpt optimization algorithm (e.g. Tree of Parzen Estimators) with the objective function and search space. This will trigger many MLflow runs, one per hyperparameters settings.
- Iterate over all runs in this experiment to find the one with best validation loss and log it in MLflow.
The search.py file implements the logic for the main step and look this this:
# search.py
from hyperopt import fmin, hp, tpe, rand
import mlflow.projects
from mlflow.tracking.client import MlflowClient
@click.command(help="Hyperparameter search with Hyperopt.")
@click.option("--max-runs", type=click.INT, default=10, help="Maximum number of runs.")
@click.option("--epochs", type=click.INT, default=500, help="Number of train steps.")
@click.option("--metric", type=click.STRING, default="rmse", help="Metric to optimize.")
@click.option("--algo", type=click.STRING, default="tpe.suggest", help="Search algorithm.")
@click.argument("data")
def search(data, max_runs, epochs, metric, algo):
tracking_client = mlflow.tracking.MlflowClient()
# initial value for the parameter to be optimized
_inf = np.finfo(np.float64).max
# define the search space for hyper-parameters
space = [
hp.uniform('lr', 1e-5, 1e-1),
]
with mlflow.start_run() as run:
exp_id = run.info.experiment_id
# run the optimization algorithm
best = fmin(
fn=train_fn(epochs, exp_id, _inf, _inf),
space=space,
algo=tpe.suggest if algo == "tpe.suggest" else rand.suggest,
max_evals=max_runs
)
mlflow.set_tag("best params", str(best))
# find all runs generated by this search
client = MlflowClient()
query = "tags.mlflow.parentRunId = '{run_id}' ".format(run_id=run.info.run_id)
runs = client.search_runs([exp_id], query)
# iterate over all runs to find best one
best_train, best_valid = _inf, _inf
best_run = None
for r in runs:
if r.data.metrics["val_rmse"] < best_val_valid:
best_run = r
best_train = r.data.metrics["train_rmse"]
best_valid = r.data.metrics["val_rmse"]
# log best run metrics as the final metrics of this run.
mlflow.set_tag("best_run", best_run.info.run_id)
mlflow.log_metrics({
"train_{}".format(metric): best_train,
"val_{}".format(metric): best_valid
})
def train_fn(epochs, null_train_loss, null_valid_loss):
...
if __name__ == '__main__':
search()
The definition of the train_fn where the call to the train step is perfomed looks like this:
# search.py
def train_fn(epochs, null_train_loss, null_valid_loss):
# Actual training function
def train(params):
lr = params
with mlflow.start_run(nested=True) as child_run:
# run the training Step and wait it finishes
p = mlflow.projects.run(
uri=".",
entry_point="train",
run_id=child_run.info.run_id,
parameters={
"data": data,
"epochs": str(epochs),
"learning_rate": str(lr)
},
experiment_id=experiment_id,
use_conda=False,
synchronous=False
)
succeeded = p.wait()
# If training finished successfully log the metrics
if succeeded:
training_run = tracking_client.get_run(p.run_id)
metrics = training_run.data.metrics
train_loss = metrics["train_{}".format(metric)]
valid_loss = metrics["val_{}".format(metric)]
else:
# reported failed run
tracking_client.set_terminated(p.run_id, "FAILED")
train_loss = null_train_loss
valid_loss = null_valid_loss
# log the metrics from this run
mlflow.log_metrics({
"train_{}".format(metric): train_loss,
"val_{}".format(metric) : valid_loss
})
# return validation loss which will be used by the optimization algorithm
return valid_loss
return train
Results
After running the project, e.g. directly call the train step as follows, we can visualize the results (in this case the validation losses) of every run from the MLflow UI.
$ mlflow run -e train --experiment-name hyperopt .
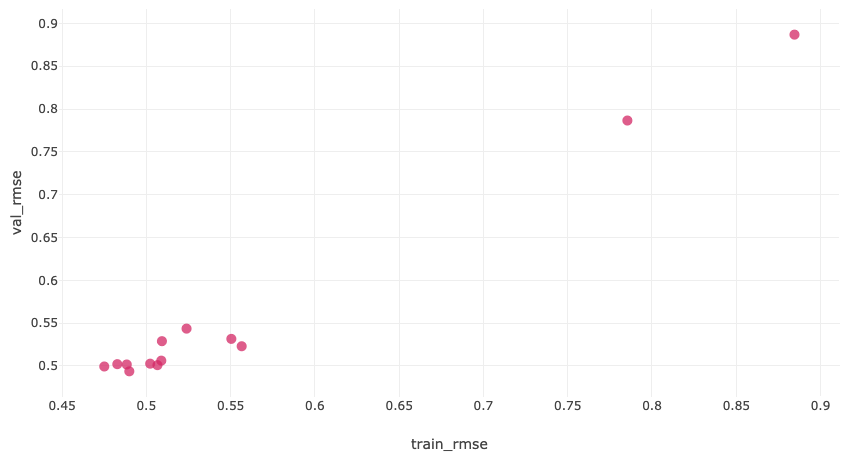 |
|---|
| Training vs. validation losses for every MLflow run |