
Spark on Kubernetes the Operator way - part 2
15 Jul 2020 by dzlab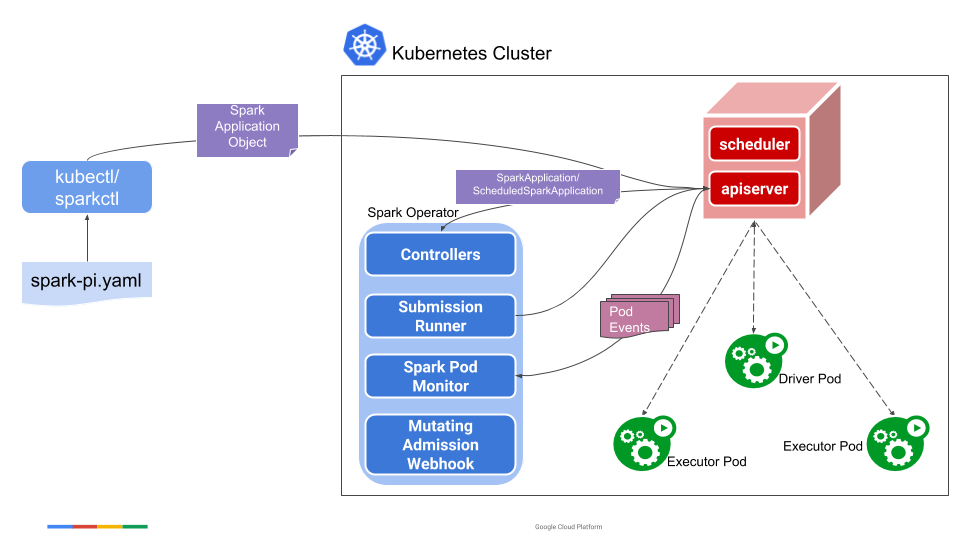
In the first part of running Spark on Kubernetes using the Spark Operator (link) we saw how to setup the Operator and run one of the examples project. As a follow up, in this second part we will:
- Setup Minikube with a local Docker Registry to host Docker images and makes available to Kubernetes.
- Create a scala project that contains a simple Spark application
- Build a Docker image for this project using sbt-native-packager and test it localy.
- Create a Kubernetes deployment manifest that describes how this Spark application has to be deployed using the
SparkApplicaionCRD. - Sumbit the manifest and monitor the application execution
Code and scripts used in this project are hosted on this Github repo spark-k8s.
1. Minikube with Registry
We need a Kubernetes cluster and a Docker Regitry, we will use Minikube and a local Regitry which is vert convenient for developpment.
$ minikube start --driver=hyperkit --memory 8192 --cpus 4 --insecure-registry "10.0.0.0/24"
😄 minikube v1.12.1 on Darwin 10.15.6
✨ Using the hyperkit driver based on user configuration
💾 Downloading driver docker-machine-driver-hyperkit:
> docker-machine-driver-hyperkit.sha256: 65 B / 65 B [---] 100.00% ? p/s 0s
> docker-machine-driver-hyperkit: 10.90 MiB / 10.90 MiB 100.00% 14.69 MiB
🔑 The 'hyperkit' driver requires elevated permissions. The following commands will be executed:
$ sudo chown root:wheel /Users/dzlab/.minikube/bin/docker-machine-driver-hyperkit
$ sudo chmod u+s /Users/dzlab/.minikube/bin/docker-machine-driver-hyperkit
Password:
💿 Downloading VM boot image ...
> minikube-v1.12.0.iso.sha256: 65 B / 65 B [-------------] 100.00% ? p/s 0s
> minikube-v1.12.0.iso: 173.57 MiB / 173.57 MiB [] 100.00% 55.81 MiB p/s 3s
👍 Starting control plane node minikube in cluster minikube
💾 Downloading Kubernetes v1.18.3 preload ...
> preloaded-images-k8s-v4-v1.18.3-docker-overlay2-amd64.tar.lz4: 526.27 MiB
🔥 Creating hyperkit VM (CPUs=4, Memory=8192MB, Disk=20000MB) ...
🐳 Preparing Kubernetes v1.18.3 on Docker 19.03.12 ...
🔎 Verifying Kubernetes components...
🌟 Enabled addons: default-storageclass, storage-provisioner
🏄 Done! kubectl is now configured to use "minikube"
Switch to Minikube Docker daemon so that all the subsequent Docker commands will be forwarded to it:
$ eval $(minikube docker-env)
Enable the Docker Registry on Minikube using addons. This exposes its port 5000 on the minikube’s virtual machine ip address.
$ minikube addons enable registry
🔎 Verifying registry addon...
🌟 The 'registry' addon is enabled
We can confirm now that the Registry is running using docker ps
$ docker ps | grep registry
b000c027846b gcr.io/google_containers/kube-registry-proxy "/bin/boot" 44 seconds ago Up 43 seconds k8s_registry-proxy_registry-proxy-h552c_kube-system_e68e762f-d1d4-4ac3-a441-5c707355098c_0
5781e647aa54 registry.hub.docker.com/library/registry "/entrypoint.sh /etc…" 51 seconds ago Up 50 seconds k8s_registry_registry-rkpv2_kube-system_70995826-aac0-4c65-81b0-1ffdef648378_0
4696d96aa103 k8s.gcr.io/pause:3.2 "/pause" 55 seconds ago Up 54 seconds 0.0.0.0:5000->80/tcp k8s_POD_registry-proxy-h552c_kube-system_e68e762f-d1d4-4ac3-a441-5c707355098c_0
792bb6772011 k8s.gcr.io/pause:3.2 "/pause" 55 seconds ago Up 54 seconds k8s_POD_registry-rkpv2_kube-system_70995826-aac0-4c65-81b0-1ffdef648378_0
A last check to confirm that Docker Registry is exposed on the Minikube IP address is the curl the catalog of repository as follows
$ curl -s $(minikube ip):5000/v2/_catalog
{"repositories": []}
Now we have a Kubernetes cluster up and running, with a Docker Registry to host Docker images. From now we need to setup Spark Operator as previously done in (part 1). Once Spark Operator is setup to manage Spark applications we can jump on the next steps.
2. Create Spark application
With the infrastructure in place, we can build the Spark application to be run on top of this infra. We will use a simple Spark job, that runs and calculate Pi, obviously we could use something more elegant but the focus of the article on the infrastrucutre and how to package Spark applications to run on Kubernetes. The entry point class SparkJob.scala looks like this:
package dzlab
import org.apache.spark.{SparkConf, SparkContext}
object SparkJob extends App {
val conf = new SparkConf()
.setAppName("Spark Job")
.setIfMissing("spark.master", "local[*]")
val sc = new SparkContext(conf)
val NUM_SAMPLES = 100000000
val count = sc.parallelize(1 to NUM_SAMPLES).filter { _ =>
val x = math.random
val y = math.random
x * x + y * y < 1
}.count()
println(s"Pi is roughly ${4.0 * count / NUM_SAMPLES}")
}
The other important file in this project is the build.sbt which defines how the project is packaged, what base image to use, and where to publish the final Docker image.
val sparkVersion = "2.4.5"
scalaVersion in ThisBuild := "2.12.0"
val sparkLibs = Seq(
"org.apache.spark" %% "spark-core" % sparkVersion,
"org.apache.spark" %% "spark-sql" % sparkVersion
)
// JAR build settings
lazy val commonSettings = Seq(
organization := "dzlab",
version := "0.1",
scalaSource in Compile := baseDirectory.value / "src",
scalaSource in Test := baseDirectory.value / "test",
resourceDirectory in Test := baseDirectory.value / "test" / "resources",
javacOptions ++= Seq(),
scalacOptions ++= Seq(
"-deprecation",
"-feature",
"-language:implicitConversions",
"-language:postfixOps"
),
libraryDependencies ++= sparkLibs
)
// Docker Image build settings
dockerBaseImage := "gcr.io/spark-operator/spark:v" + sparkVersion
val registry = "192.168.64.11:5000"
lazy val root = (project in file("."))
.enablePlugins(
DockerPlugin,
JavaAppPackaging
)
.settings(
name := "spark-k8s",
commonSettings,
dockerAliases ++= Seq(
dockerAlias.value.withRegistryHost(Some(registry))
),
mainClass in (Compile, run) := Some("dzlab.SparkJob")
)
Notice the following important variables in this build configuration file:
dockerBaseImage: set to a Spark Operator image which we need to use as base Docker image.registry: set the Minikube VM IP address and port 5000 on which Docker Registry is running.
3. Build Docker image
Now as we have the infra and the project setup, we can build the Docker image for our Spark example project using sbt docker:publishLocal like this:
$ sbt docker:publishLocal
[info] Loading global plugins from /Users/dzlab/.sbt/0.13/plugins
[info] Loading project definition from /Users/dzlab/Projects/spark-k8s/project
[info] Set current project to spark-k8s (in build file:/Users/dzlab/Projects/spark-k8s/)
[info] Packaging /Users/dzlab/Projects/spark-k8s/target/scala-2.12/spark-k8s_2.12-0.1-sources.jar ...
[info] Done packaging.
[info] Wrote /Users/dzlab/Projects/spark-k8s/target/scala-2.12/spark-k8s_2.12-0.1.pom
[info] Main Scala API documentation to /Users/dzlab/Projects/spark-k8s/target/scala-2.12/api...
[info] Compiling 1 Scala source to /Users/dzlab/Projects/spark-k8s/target/scala-2.12/classes...
model contains 3 documentable templates
[info] Main Scala API documentation successful.
[info] Packaging /Users/dzlab/Projects/spark-k8s/target/scala-2.12/spark-k8s_2.12-0.1-javadoc.jar ...
[info] Done packaging.
[info] Packaging /Users/dzlab/Projects/spark-k8s/target/scala-2.12/spark-k8s_2.12-0.1.jar ...
[info] Done packaging.
[info] Sending build context to Docker daemon 103.9MB
[info] Step 1/7 : FROM gcr.io/spark-operator/spark:v2.4.5
[info] ---> 775e46820946
[info] Step 2/7 : WORKDIR /opt/docker
[info] ---> Using cache
[info] ---> 0cb526d5da5e
[info] Step 3/7 : ADD opt /opt
[info] ---> 7fa78fca660d
[info] Step 4/7 : RUN ["chown", "-R", "daemon:daemon", "."]
[info] ---> Running in c6a7f951555d
[info] Removing intermediate container c6a7f951555d
[info] ---> 0afc2580ae9c
[info] Step 5/7 : USER daemon
[info] ---> Running in 2239c4f9a0dc
[info] Removing intermediate container 2239c4f9a0dc
[info] ---> 37cf0420527f
[info] Step 6/7 : ENTRYPOINT ["bin/spark-k8s"]
[info] ---> Running in 6df7c84d8312
[info] Removing intermediate container 6df7c84d8312
[info] ---> de1117b1aaa4
[info] Step 7/7 : CMD []
[info] ---> Running in 25476927fa0a
[info] Removing intermediate container 25476927fa0a
[info] ---> 114cb5ef3a37
[info] Successfully built 114cb5ef3a37
[info] Successfully tagged spark-k8s:0.1
[info] Built image spark-k8s:0.1
[success] Total time: 13 s, completed Jul 17, 2020 7:26:44 PM
Notice in the output of the Docker build that the default working dir is /opt/docker and the final jar will be located at /opt/docker/lib/dzlab.spark-k8s-0.1.jar.
Now we can test the Docker image locally before submitting it to Kubernetes to check that everything is working properly:
$ docker run --rm -p 4040:4040 spark-k8s:0.1
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
20/07/18 02:24:30 INFO SparkContext: Running Spark version 2.4.5
20/07/18 02:24:30 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
20/07/18 02:24:30 INFO SparkContext: Submitted application: Spark Job
20/07/18 02:24:30 INFO SecurityManager: Changing view acls to: daemon
20/07/18 02:24:30 INFO SecurityManager: Changing modify acls to: daemon
20/07/18 02:24:30 INFO SecurityManager: Changing view acls groups to:
20/07/18 02:24:30 INFO SecurityManager: Changing modify acls groups to:
20/07/18 02:24:30 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(daemon); groups with view permissions: Set(); users with modify permissions: Set(daemon); groups with modify permissions: Set()
20/07/18 02:24:31 INFO Utils: Successfully started service 'sparkDriver' on port 41353.
20/07/18 02:24:31 INFO SparkEnv: Registering MapOutputTracker
20/07/18 02:24:31 INFO SparkEnv: Registering BlockManagerMaster
20/07/18 02:24:31 INFO BlockManagerMasterEndpoint: Using org.apache.spark.storage.DefaultTopologyMapper for getting topology information
20/07/18 02:24:31 INFO BlockManagerMasterEndpoint: BlockManagerMasterEndpoint up
20/07/18 02:24:31 INFO DiskBlockManager: Created local directory at /tmp/blockmgr-5385b3a6-a5a4-4846-92a6-baf61bfe4b7e
20/07/18 02:24:31 INFO MemoryStore: MemoryStore started with capacity 882.6 MB
20/07/18 02:24:31 INFO SparkEnv: Registering OutputCommitCoordinator
20/07/18 02:24:31 INFO Utils: Successfully started service 'SparkUI' on port 4040.
20/07/18 02:24:31 INFO SparkUI: Bound SparkUI to 0.0.0.0, and started at http://07a8fc0e650b:4040
20/07/18 02:24:31 INFO Executor: Starting executor ID driver on host localhost
20/07/18 02:24:31 INFO Utils: Successfully started service 'org.apache.spark.network.netty.NettyBlockTransferService' on port 37487.
20/07/18 02:24:31 INFO NettyBlockTransferService: Server created on 07a8fc0e650b:37487
20/07/18 02:24:31 INFO BlockManager: Using org.apache.spark.storage.RandomBlockReplicationPolicy for block replication policy
20/07/18 02:24:31 INFO BlockManagerMaster: Registering BlockManager BlockManagerId(driver, 07a8fc0e650b, 37487, None)
20/07/18 02:24:31 INFO BlockManagerMasterEndpoint: Registering block manager 07a8fc0e650b:37487 with 882.6 MB RAM, BlockManagerId(driver, 07a8fc0e650b, 37487, None)
20/07/18 02:24:31 INFO BlockManagerMaster: Registered BlockManager BlockManagerId(driver, 07a8fc0e650b, 37487, None)
20/07/18 02:24:31 INFO BlockManager: Initialized BlockManager: BlockManagerId(driver, 07a8fc0e650b, 37487, None)
20/07/18 02:24:32 INFO SparkContext: Starting job: count at SparkJob.scala:14
20/07/18 02:24:32 INFO DAGScheduler: Got job 0 (count at SparkJob.scala:14) with 6 output partitions
20/07/18 02:24:32 INFO DAGScheduler: Final stage: ResultStage 0 (count at SparkJob.scala:14)
20/07/18 02:24:32 INFO DAGScheduler: Parents of final stage: List()
20/07/18 02:24:32 INFO DAGScheduler: Missing parents: List()
20/07/18 02:24:32 INFO DAGScheduler: Submitting ResultStage 0 (MapPartitionsRDD[1] at filter at SparkJob.scala:14), which has no missing parents
20/07/18 02:24:32 INFO MemoryStore: Block broadcast_0 stored as values in memory (estimated size 3.0 KB, free 882.6 MB)
20/07/18 02:24:32 INFO MemoryStore: Block broadcast_0_piece0 stored as bytes in memory (estimated size 1783.0 B, free 882.6 MB)
20/07/18 02:24:32 INFO BlockManagerInfo: Added broadcast_0_piece0 in memory on 07a8fc0e650b:37487 (size: 1783.0 B, free: 882.6 MB)
20/07/18 02:24:32 INFO SparkContext: Created broadcast 0 from broadcast at DAGScheduler.scala:1163
20/07/18 02:24:32 INFO DAGScheduler: Submitting 6 missing tasks from ResultStage 0 (MapPartitionsRDD[1] at filter at SparkJob.scala:14) (first 15 tasks are for partitions Vector(0, 1, 2, 3, 4, 5))
20/07/18 02:24:32 INFO TaskSchedulerImpl: Adding task set 0.0 with 6 tasks
20/07/18 02:24:32 INFO TaskSetManager: Starting task 0.0 in stage 0.0 (TID 0, localhost, executor driver, partition 0, PROCESS_LOCAL, 7391 bytes)
20/07/18 02:24:32 INFO TaskSetManager: Starting task 1.0 in stage 0.0 (TID 1, localhost, executor driver, partition 1, PROCESS_LOCAL, 7391 bytes)
20/07/18 02:24:32 INFO TaskSetManager: Starting task 2.0 in stage 0.0 (TID 2, localhost, executor driver, partition 2, PROCESS_LOCAL, 7391 bytes)
20/07/18 02:24:32 INFO TaskSetManager: Starting task 3.0 in stage 0.0 (TID 3, localhost, executor driver, partition 3, PROCESS_LOCAL, 7391 bytes)
20/07/18 02:24:32 INFO TaskSetManager: Starting task 4.0 in stage 0.0 (TID 4, localhost, executor driver, partition 4, PROCESS_LOCAL, 7391 bytes)
20/07/18 02:24:32 INFO TaskSetManager: Starting task 5.0 in stage 0.0 (TID 5, localhost, executor driver, partition 5, PROCESS_LOCAL, 7448 bytes)
20/07/18 02:24:32 INFO Executor: Running task 2.0 in stage 0.0 (TID 2)
20/07/18 02:24:32 INFO Executor: Running task 5.0 in stage 0.0 (TID 5)
20/07/18 02:24:32 INFO Executor: Running task 4.0 in stage 0.0 (TID 4)
20/07/18 02:24:32 INFO Executor: Running task 0.0 in stage 0.0 (TID 0)
20/07/18 02:24:32 INFO Executor: Running task 3.0 in stage 0.0 (TID 3)
20/07/18 02:24:32 INFO Executor: Running task 1.0 in stage 0.0 (TID 1)
20/07/18 02:24:32 INFO Executor: Finished task 0.0 in stage 0.0 (TID 0). 752 bytes result sent to driver
20/07/18 02:24:32 INFO Executor: Finished task 5.0 in stage 0.0 (TID 5). 752 bytes result sent to driver
20/07/18 02:24:32 INFO Executor: Finished task 4.0 in stage 0.0 (TID 4). 752 bytes result sent to driver
20/07/18 02:24:32 INFO Executor: Finished task 1.0 in stage 0.0 (TID 1). 752 bytes result sent to driver
20/07/18 02:24:32 INFO Executor: Finished task 2.0 in stage 0.0 (TID 2). 752 bytes result sent to driver
20/07/18 02:24:32 INFO Executor: Finished task 3.0 in stage 0.0 (TID 3). 752 bytes result sent to driver
20/07/18 02:24:32 INFO TaskSetManager: Finished task 5.0 in stage 0.0 (TID 5) in 464 ms on localhost (executor driver) (1/6)
20/07/18 02:24:32 INFO TaskSetManager: Finished task 4.0 in stage 0.0 (TID 4) in 469 ms on localhost (executor driver) (2/6)
20/07/18 02:24:33 INFO TaskSetManager: Finished task 0.0 in stage 0.0 (TID 0) in 501 ms on localhost (executor driver) (3/6)
20/07/18 02:24:33 INFO TaskSetManager: Finished task 1.0 in stage 0.0 (TID 1) in 475 ms on localhost (executor driver) (4/6)
20/07/18 02:24:33 INFO TaskSetManager: Finished task 2.0 in stage 0.0 (TID 2) in 475 ms on localhost (executor driver) (5/6)
20/07/18 02:24:33 INFO TaskSetManager: Finished task 3.0 in stage 0.0 (TID 3) in 477 ms on localhost (executor driver) (6/6)
20/07/18 02:24:33 INFO TaskSchedulerImpl: Removed TaskSet 0.0, whose tasks have all completed, from pool
20/07/18 02:24:33 INFO DAGScheduler: ResultStage 0 (count at SparkJob.scala:14) finished in 0.672 s
20/07/18 02:24:33 INFO DAGScheduler: Job 0 finished: count at SparkJob.scala:14, took 0.752013 s
Pi is roughly 3.1516
20/07/18 02:24:33 INFO SparkContext: Invoking stop() from shutdown hook
20/07/18 02:24:33 INFO SparkUI: Stopped Spark web UI at http://07a8fc0e650b:4040
20/07/18 02:24:33 INFO MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped!
20/07/18 02:24:33 INFO MemoryStore: MemoryStore cleared
20/07/18 02:24:33 INFO BlockManager: BlockManager stopped
20/07/18 02:24:33 INFO BlockManagerMaster: BlockManagerMaster stopped
20/07/18 02:24:33 INFO OutputCommitCoordinator$OutputCommitCoordinatorEndpoint: OutputCommitCoordinator stopped!
20/07/18 02:24:33 INFO SparkContext: Successfully stopped SparkContext
20/07/18 02:24:33 INFO ShutdownHookManager: Shutdown hook called
20/07/18 02:24:33 INFO ShutdownHookManager: Deleting directory /tmp/spark-bc240503-ee25-498b-bfeb-6a5af23cb21d
4. Create Kubernetes deployment
With the Docker Registry and the location of the project Jar within the previously built Docker image, we can write the deployment manifest to be submitted to Kubernetes spark-k8s.yaml. It should look the this:
apiVersion: "sparkoperator.k8s.io/v1beta2"
kind: SparkApplication
metadata:
name: spark-k8s
namespace: spark-apps
spec:
type: Scala
mode: cluster
image: "192.168.64.11:5000/spark-k8s:0.1"
imagePullPolicy: Always
mainClass: dzlab.SparkJob
mainApplicationFile: "local:///opt/docker/lib/dzlab.spark-k8s-0.1.jar"
sparkVersion: "2.4.5"
restartPolicy:
type: Never
volumes:
- name: "test-volume"
hostPath:
path: "/tmp"
type: Directory
driver:
cores: 1
coreLimit: "1200m"
memory: "512m"
labels:
version: 2.4.5
serviceAccount: spark
volumeMounts:
- name: "test-volume"
mountPath: "/tmp"
executor:
cores: 1
instances: 1
memory: "512m"
labels:
version: 2.4.5
volumeMounts:
- name: "test-volume"
mountPath: "/tmp"
5. Submit Spark application
Now we can submit this sample Spark project and run it on minikube with
$ kubectl apply -f spark-k8s.yaml
sparkapplication.sparkoperator.k8s.io/spark-k8s created
It is also possible to simply run it as a deployment (it is only possible in our case because the Spark job is simple)
$ kubectl create deployment spark-k8s --image=$(minikube ip):5000/spark-k8s:0.1
deployment.apps/spark-k8s created
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
spark-k8s-58ff6c74d5-c7lx7 1/1 Running 0 6s
Check the logs of the pod to see the Spark job output
$ kubectl logs spark-k8s-58ff6c74d5-c7lx7
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
20/07/26 19:02:55 INFO SparkContext: Running Spark version 2.4.5
20/07/26 19:02:55 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
20/07/26 19:02:55 INFO SparkContext: Submitted application: Spark Job
20/07/26 19:02:55 INFO SecurityManager: Changing view acls to: demiourgos728
20/07/26 19:02:55 INFO SecurityManager: Changing modify acls to: demiourgos728
20/07/26 19:02:55 INFO SecurityManager: Changing view acls groups to:
20/07/26 19:02:55 INFO SecurityManager: Changing modify acls groups to:
20/07/26 19:02:55 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(demiourgos728); groups with view permissions: Set(); users with modify permissions: Set(demiourgos728); groups with modify permissions: Set()
20/07/26 19:02:55 INFO Utils: Successfully started service 'sparkDriver' on port 40237.
20/07/26 19:02:55 INFO SparkEnv: Registering MapOutputTracker
20/07/26 19:02:55 INFO SparkEnv: Registering BlockManagerMaster
20/07/26 19:02:55 INFO BlockManagerMasterEndpoint: Using org.apache.spark.storage.DefaultTopologyMapper for getting topology information
20/07/26 19:02:55 INFO BlockManagerMasterEndpoint: BlockManagerMasterEndpoint up
20/07/26 19:02:55 INFO DiskBlockManager: Created local directory at /tmp/blockmgr-9caab0d9-7709-46b7-9529-a9a7a04c6831
20/07/26 19:02:55 INFO MemoryStore: MemoryStore started with capacity 976.5 MB
20/07/26 19:02:56 INFO SparkEnv: Registering OutputCommitCoordinator
20/07/26 19:02:56 INFO Utils: Successfully started service 'SparkUI' on port 4040.
20/07/26 19:02:56 INFO SparkUI: Bound SparkUI to 0.0.0.0, and started at http://spark-k8s-58ff6c74d5-c7lx7:4040
20/07/26 19:02:56 INFO Executor: Starting executor ID driver on host localhost
20/07/26 19:02:56 INFO Utils: Successfully started service 'org.apache.spark.network.netty.NettyBlockTransferService' on port 43327.
20/07/26 19:02:56 INFO NettyBlockTransferService: Server created on spark-k8s-58ff6c74d5-c7lx7:43327
20/07/26 19:02:56 INFO BlockManager: Using org.apache.spark.storage.RandomBlockReplicationPolicy for block replication policy
20/07/26 19:02:56 INFO BlockManagerMaster: Registering BlockManager BlockManagerId(driver, spark-k8s-58ff6c74d5-c7lx7, 43327, None)
20/07/26 19:02:56 INFO BlockManagerMasterEndpoint: Registering block manager spark-k8s-58ff6c74d5-c7lx7:43327 with 976.5 MB RAM, BlockManagerId(driver, spark-k8s-58ff6c74d5-c7lx7, 43327, None)
20/07/26 19:02:56 INFO BlockManagerMaster: Registered BlockManager BlockManagerId(driver, spark-k8s-58ff6c74d5-c7lx7, 43327, None)
20/07/26 19:02:56 INFO BlockManager: Initialized BlockManager: BlockManagerId(driver, spark-k8s-58ff6c74d5-c7lx7, 43327, None)
20/07/26 19:02:56 INFO SparkContext: Starting job: count at SparkJob.scala:14
20/07/26 19:02:56 INFO DAGScheduler: Got job 0 (count at SparkJob.scala:14) with 1 output partitions
20/07/26 19:02:56 INFO DAGScheduler: Final stage: ResultStage 0 (count at SparkJob.scala:14)
20/07/26 19:02:56 INFO DAGScheduler: Parents of final stage: List()
20/07/26 19:02:56 INFO DAGScheduler: Missing parents: List()
20/07/26 19:02:56 INFO DAGScheduler: Submitting ResultStage 0 (MapPartitionsRDD[1] at filter at SparkJob.scala:14), which has no missing parents
20/07/26 19:02:56 INFO MemoryStore: Block broadcast_0 stored as values in memory (estimated size 3.0 KB, free 976.5 MB)
20/07/26 19:02:57 INFO MemoryStore: Block broadcast_0_piece0 stored as bytes in memory (estimated size 1780.0 B, free 976.5 MB)
20/07/26 19:02:57 INFO BlockManagerInfo: Added broadcast_0_piece0 in memory on spark-k8s-58ff6c74d5-c7lx7:43327 (size: 1780.0 B, free: 976.5 MB)
20/07/26 19:02:57 INFO SparkContext: Created broadcast 0 from broadcast at DAGScheduler.scala:1163
20/07/26 19:02:57 INFO DAGScheduler: Submitting 1 missing tasks from ResultStage 0 (MapPartitionsRDD[1] at filter at SparkJob.scala:14) (first 15 tasks are for partitions Vector(0))
20/07/26 19:02:57 INFO TaskSchedulerImpl: Adding task set 0.0 with 1 tasks
20/07/26 19:02:57 INFO TaskSetManager: Starting task 0.0 in stage 0.0 (TID 0, localhost, executor driver, partition 0, PROCESS_LOCAL, 7448 bytes)
20/07/26 19:02:57 INFO Executor: Running task 0.0 in stage 0.0 (TID 0)
20/07/26 19:03:03 INFO Executor: Finished task 0.0 in stage 0.0 (TID 0). 752 bytes result sent to driver
20/07/26 19:03:03 INFO TaskSetManager: Finished task 0.0 in stage 0.0 (TID 0) in 6736 ms on localhost (executor driver) (1/1)
20/07/26 19:03:03 INFO TaskSchedulerImpl: Removed TaskSet 0.0, whose tasks have all completed, from pool
20/07/26 19:03:03 INFO DAGScheduler: ResultStage 0 (count at SparkJob.scala:14) finished in 6.896 s
20/07/26 19:03:03 INFO DAGScheduler: Job 0 finished: count at SparkJob.scala:14, took 6.946354 s
Pi is roughly 3.1417062
20/07/26 19:03:03 INFO SparkContext: Invoking stop() from shutdown hook
20/07/26 19:03:03 INFO SparkUI: Stopped Spark web UI at http://spark-k8s-58ff6c74d5-c7lx7:4040
20/07/26 19:03:03 INFO MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped!
20/07/26 19:03:03 INFO MemoryStore: MemoryStore cleared
20/07/26 19:03:03 INFO BlockManager: BlockManager stopped
20/07/26 19:03:03 INFO BlockManagerMaster: BlockManagerMaster stopped
20/07/26 19:03:03 INFO OutputCommitCoordinator$OutputCommitCoordinatorEndpoint: OutputCommitCoordinator stopped!
20/07/26 19:03:03 INFO SparkContext: Successfully stopped SparkContext
20/07/26 19:03:03 INFO ShutdownHookManager: Shutdown hook called
20/07/26 19:03:03 INFO ShutdownHookManager: Deleting directory /tmp/spark-8dc49a3f-f57c-4db5-8e8c-f8ded398da6f
Now as we have a Spark application running on Kubernetes, we may want to enable monitoring the collect runtime metrics. Check other posts on monitoring (link).