


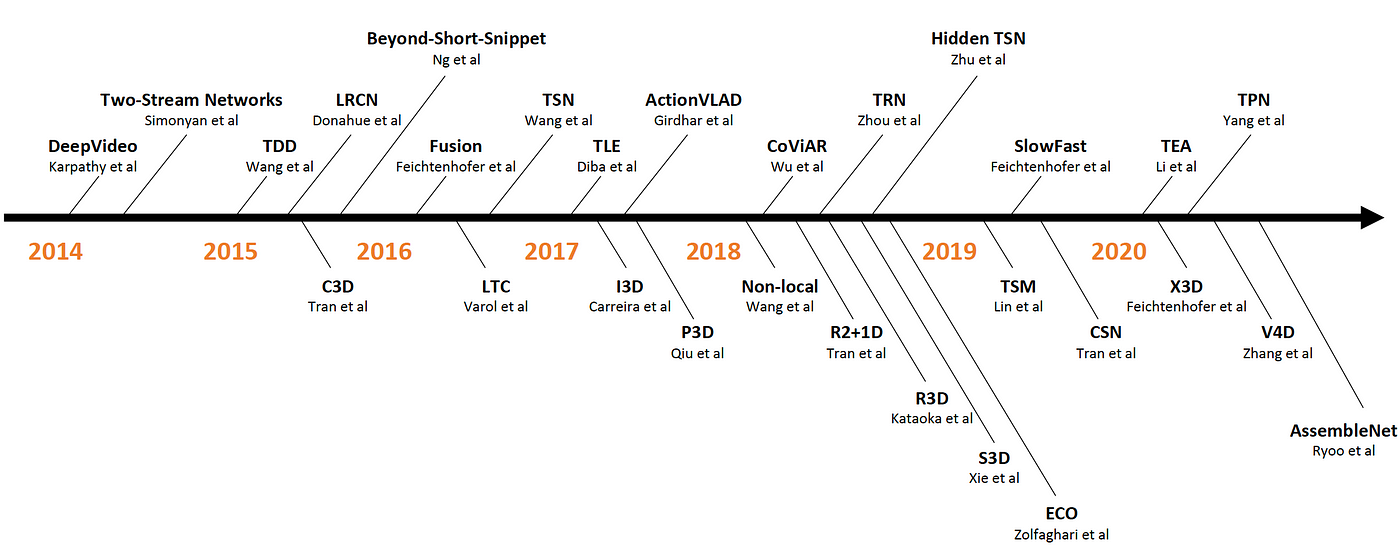
Action recognition is a very hot topic in the broader video processing and understanding research. The below timeline illustrates how reaseracher are getting more interested in the area and proposing SOTA models to push the field further. source
Training a model from scratch to perform this task is very challenging due to the nature of the task that is not only associated with classifying the content of an image, but also includes a temporal component. In this article, we will leaverage TensorFlow Hub and pick one model from this large model zoo to perform Video Action Recognition effortlessly. Specifically we will use DeepMind's Inflated 3D Convnet (I3D) model which was training on DeepMind Kinetics dataset.
First, let's import all the needed dependencies
import os
import random
import re
import ssl
import tempfile
from pathlib import Path
from urllib import request
import matplotlib.pyplot as plt
import cv2
import imageio
import numpy as np
import tensorflow as tf
import tensorflow_hub as tfhub
from IPython.display import Image
from wordcloud import WordCloud
Dataset
There is lot datasets, you can find more here, we will be using UCF101 Action Recognition dataset which is available for public download here. We will not be using the entirety of the dataset but just picking a random video.
The different activities available in the UCF101 Action Recognition dataset are as follows:

To list and download videos from the UCF101 website we define the following helper class that exposes multiple functions to make it easy to get a video locally.
class UCFDataset(object):
def __init__(self):
self.UNVERIFIED_CONTEXT = ssl._create_unverified_context()
self.UCF_ROOT = 'https://www.crcv.ucf.edu/THUMOS14/UCF101/UCF101/'
# Temporary directory to cache the downloaded videos
self.CACHE_DIR = tempfile.mkdtemp()
self.videos_list = self.download_videos_list()
def _read(self, url):
"""Read data for the given url"""
return request.urlopen(url,context=self.UNVERIFIED_CONTEXT).read()
def download_videos_list(self):
"""Dowload the list of video names and direct download urls"""
index = (self._read(self.UCF_ROOT).decode('utf-8'))
videos = re.findall('(v_[\w]+\.avi)', index)
return sorted(set(videos))
def __getitem__(self, video_name):
"""Download a specific video by name"""
cache_path = os.path.join(self.CACHE_DIR, video_name)
if not os.path.exists(cache_path):
url = request.urljoin(self.UCF_ROOT, video_name)
response = self._read(url)
with open(cache_path, 'wb') as f:
f.write(response)
return cache_path
def download_random_video(self):
"""Download a random video from the dataset"""
video_name = random.choice(self.videos_list)
return self.__getitem__(video_name)
Define a helper function to crop a squared selection in the center of a frame
def crop_center(frame):
height, width = frame.shape[:2]
smallest_dimension = min(width, height)
x_start = (width // 2) - (smallest_dimension // 2)
x_end = x_start + smallest_dimension
y_start = (height // 2) - (smallest_dimension // 2)
y_end = y_start + smallest_dimension
roi = frame[y_start:y_end, x_start:x_end]
return roi
Define a helper function to read a video by path, take up to max_frames frames from it, and return a resized to (224, 224, 3) selection of those frames.
def read_video(path, max_frames=32, resize=(224, 224)):
capture = cv2.VideoCapture(path)
frames = []
while len(frames) <= max_frames:
frame_read, frame = capture.read()
if not frame_read:
break
frame = crop_center(frame)
frame = cv2.resize(frame, resize)
frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
frames.append(frame)
capture.release()
frames = np.array(frames)
return frames / 255.
To be able to visualize the video on this notebook, we need function to create a save a collection of frames as a GIF.
def save_as_gif(images, video_name):
filename = f'./{video_name}.gif'
converted_images = np.clip(images * 255, 0, 255)
converted_images = converted_images.astype(np.uint8)
imageio.mimsave(filename, converted_images,fps=25)
return filename
Now, we can download the list of videos from the UFC101 dataset
dataset = UCFDataset()
First, let's get the labels file from the Kinetics dataset that was used to train the I3D model
KINETICS_URL = 'https://raw.githubusercontent.com/deepmind/kinetics-i3d/master/data/label_map.txt'
The following helper function download the labels from the previous link
def fetch_kinetics_labels():
with request.urlopen(KINETICS_URL) as f:
labels = [line.decode('utf-8').strip() for line in f.readlines()]
return labels
Download the list of labels, and diplay them in a wordcloud
LABELS = fetch_kinetics_labels()
wordcloud = WordCloud(collocations = False, background_color = 'white')
wordcloud = wordcloud.generate(' '.join(LABELS))
plt.figure(figsize=(10, 12))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis("off")
plt.show()

Now let's download the I3D model from TensorFlow Hub
model_path = 'https://tfhub.dev/deepmind/i3d-kinetics-400/1'
model = tfhub.load(model_path)
model = model.signatures['default']
def predict(model, labels, sample_video):
model_input = tf.constant(sample_video, dtype=tf.float32)
model_input = model_input[tf.newaxis, ...]
logits = model(model_input)['default'][0]
probabilities = tf.nn.softmax(logits)
print('Top actions:')
for i in np.argsort(probabilities)[::-1][:5]:
if probabilities[i] < 0.01:
break
print(f'{labels[i]}: {probabilities[i] *100:5.2f}%')
Define helper function to pick a random video, save its frames as GIF
def download_random_video():
video_path = dataset.download_random_video()
sample_video = read_video(video_path)
video_name = Path(video_path).stem
gif_path = save_as_gif(sample_video, video_name)
return sample_video, gif_path
Pick a random video, display the resulting GIF
sample_video, gif_path = download_random_video()
Image(open(gif_path,'rb').read())

Pass the video through the I3D network to obtain the predicted actions
predict(model, LABELS, sample_video)
Try another video
sample_video, gif_path = download_random_video()
Image(open(gif_path,'rb').read())

predict(model, LABELS, sample_video)
See how the model is able to acurately predict the action in the video. You can try with other video as an exercise.